

Ah, the iconic 3.5″ hard drive, now approaching massive 18 and 20 TB storage capacity. Backblaze storage pods fit 60 of these drives in a single pod, and with well over 750 petabytes of customer data under management in our data centers, we have a lot of hard drives under management.
Yet most of us have just one, or only a few of these massive drives at a time storing our most valuable data. Just how safe are those hard drives in your office or studio? Have you ever thought about all the awful, terrible things that can happen to a hard drive? And what are they, exactly?
It turns out there are a host of obvious physical dangers, but also other, less obvious, errors that can affect the data stored on your hard drives, as well.
Dividing by One
It’s tempting to store all of your content on a single hard drive. After all, the capacity of these drives gets larger and larger, and they offer great performance of up to 150 MB/s. It’s true that flash-based hard drives are far faster, but the dollars per gigabyte price is also higher, so for now, the traditional 3.5″ hard drive holds most data today.
However, having all of your precious content on a single, spinning hard drive is a true tightrope without a net experience. Here’s why.
DriveSaver Failure Analysis by the Numbers
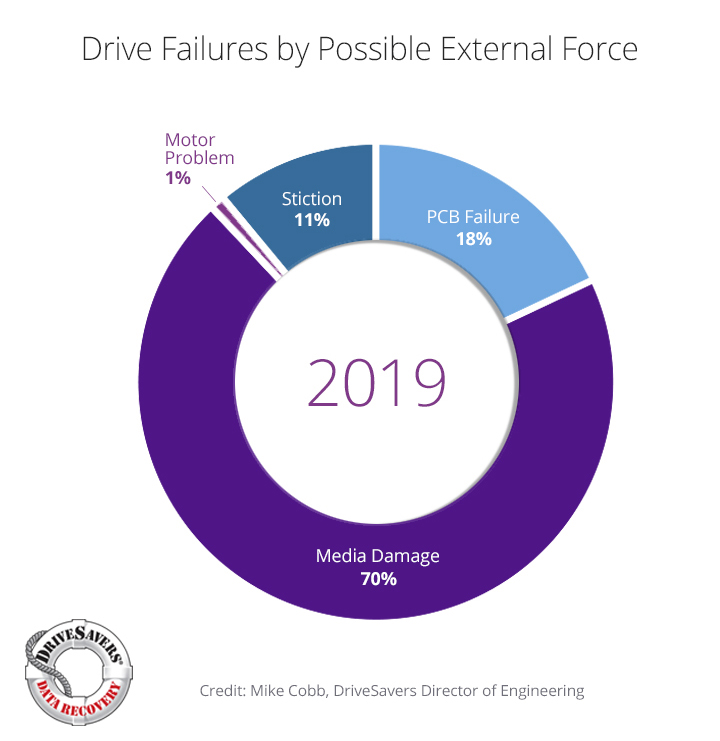
I asked our friends at DriveSavers, specialists in recovering data from drives and other storage devices, for some analysis of the hard drives brought into their labs for recovery. What were the primary causes of failure?
Reason One: Media Damage
The number one reason, accounting for 70 percent of failures, is media damage, including full head crashes.
Modern hard drives stuff multiple, ultra thin platters inside that 3.5 inch metal package. These platters spin furiously at 5400 or 7200 revolutions per minute — that’s 90 or 120 revolutions per second! The heads that read and write magnetic data on them sweep back and forth only 6.3 micrometers above the surface of those platters. That gap is about 1/12th the width of a human hair and a miracle of modern technology to be sure. As you can imagine, a system with such close tolerances is vulnerable to sudden shock, as evidenced by DriveSavers’ results.
This damage occurs when the platters receive shock, i.e. physical damage from impact to the drive itself. Platters have been known to shatter, or have damage to their surfaces, including a phenomenon called head crash, where the flying heads slam into the surface of the platters. Whatever the cause, the thin platters holding 1s and 0s can’t be read.
It takes a surprisingly small amount of force to generate a lot of shock energy to a hard drive. I’ve seen drives fail after simply tipping over when stood on end. More typically, drives are accidentally pushed off of a desktop, or dropped while being carried around.
A drive might look fine after a drop, but the damage may have been done. Due to their rigid construction, heavy weight, and how often they’re dropped on hard, unforgiving surfaces, these drops can easily generate the equivalent of hundreds of g-forces to the delicate internals of a hard drive.
To paraphrase an old (and morbid) parachutist joke, it’s not the fall that gets you, it’s the sudden stop!
Reason Two: PCB Failure
The next largest cause is circuit board failure, accounting for 18 percent of failed drives. Printed circuit boards (PCBs), those tiny green boards seen on the underside of hard drives, can fail in the presence of moisture or static electric discharge like any other circuit board.
Reason Three: Stiction
Next up is stiction (a portmanteau of friction and sticking), which occurs when the armatures that drive those flying heads actually get stuck in place and refuse to operate, usually after a long period of disuse. DriveSavers found that stuck armatures accounted for 11 percent of hard drive failures.
It seems counterintuitive that hard drives sitting quietly in a dark drawer might actually contribute to its failure, but I’ve seen many older hard drives pulled from a drawer and popped into a drive carrier or connected to power just go thunk. It does appear that hard drives like to be connected to power and constantly spinning and the numbers seem to bear this out.
Reason Four: Motor Failure
The last, and least common cause of hard drive failure, is hard drive motor failure, accounting for only 1 percent of failures, testament again to modern manufacturing precision and reliability.
Mitigating Hard Drive Failure Risk
So now that you’ve seen the gory numbers, here are a few recommendations to guard against the physical causes of hard drive failure.
1. Have a physical drive handling plan and follow it rigorously
If you must keep content on single hard drives in your location, make sure your team follows a few guidelines to protect against moisture, static electricity, and drops during drive handling. Keeping the drives in a dry location, storing the drives in static bags, using static discharge mats and wristbands, and putting rubber mats under areas where you’re likely to accidentally drop drives can all help.
It’s worth reviewing how you physically store drives, as well. DriveSavers tells us that the sudden impact of a heavy drawer of hard drives slamming home or yanked open quickly might possibly damage hard drives!
2. Spread failure risk across more drives and systems
Improving physical hard drive handling procedures is only a small part of a good risk-reducing strategy. You can immediately reduce the exposure of a single hard drive failure by simply keeping a copy of that valuable content on another drive.This is a common approach for videographers moving content from cameras shooting in the field back to their editing environment. By simply copying content over from one fast drive to another, the odds of both drives failing at once are less likely. This is certainly better than keeping content on only a single drive, but definitely not a great long-term solution.
Multiple drive NAS and RAID systems reduce the impact of failing drives even further. A RAID 6 system composed of eight drives not only has much faster read and write performance than a single drive, but two of its drives can fail and still serve your files, giving you time to replace those failed drives.
Mitigating Data Corruption Risk
The Risk of Bit Flips
Beyond physical damage, there’s another threat to the files stored on hard disks: small, silent bit flip errors often called data corruption or bit rot.
Bit rot errors occur when individual bits in a stream of data in files change from one state to another (positive or negative, 0 to 1, and vice versa). These errors can happen to hard drive and flash storage systems at rest, or be introduced as a file is copied from one hard drive to another.
While hard drives automatically correct single-bit flips on the fly, larger bit flips can introduce a number of errors. This can either cause the program accessing them to halt or throw an error, or perhaps worse, lead you to think that the file with the errors is fine!
Bit Flip Errors by the Book
In a landmark study of data failures in large systems, Disk failures in the real world:
What does an MTTF of 1,000,000 hours mean to you?, Bianca Schroeder and Garth A. Gibson reported that “a large number of the problems attributed to CPU and memory failures were triggered by parity errors, i.e. the number of errors is too large for the embedded error correcting code to correct them.”
Flash drives are not immune either. Bianca Shroeder recently published a similar study of flash drives, Flash Reliability in Production: The Expected and the Unexpected, and found that “…between 20-63% of drives experienced at least one of the (unrecoverable read errors) during the time it was in production. In addition, between 2-6 out of 1,000 drive days were affected.”
“These UREs are almost exclusively due to bit corruptions that ECC cannot correct. If a drive encounters a URE, the stored data cannot be read. This either results in a failed read in the user’s code, or if the drives are in a RAID group that has replication, then the data is read from a different drive.”
Exactly how prevalent bit flips are is a controversial subject, but if you’ve ever retrieved a file from an old hard drive or RAID system and see sparkles in video, corrupt document files, or lines or distortions in pictures, you’ve seen the results of these errors.
Protecting Against Bit Flip Errors
There are many approaches to catching and correcting bit flip errors. From a system designer standpoint they usually involve some combination of multiple disk storage systems, multiple copies of content, data integrity checks and corrections, including error-correcting code memory, physical component redundancy, and a file system that can tie it all together.
Backblaze has built such a system, and uses a number of techniques to detect and correct file degradation due to bit flips and deliver extremely high data durability and integrity, often in conjunction with Reed-Solomon erasure codes.
Thanks to the way object storage and Backblaze B2 works, files written to B2 are always retrieved exactly as you originally wrote them. If a file ever changes from the time you’ve written it, say, due to bit flip errors, it will either be reproduced from a redundant copy of your file, or even mathematically reconstructed with erasure codes.
So the simplest, and certainly least expensive way to get bit flip protection for the content sitting on your hard drives is to simply have another copy on cloud storage.
Resources:
- Backblaze has open-sourced our erasure code implementation
- Backblaze CTO Brian Wilson discusses how we calculated 11 nines of data durability
- Backblaze’s Brian Beach offers the source code behind our durability calculations
The Ideal Solution — Performance and Protection
With some thought, you can apply these protection steps to your environment and get the best of both worlds: the performance of your content on fast, local hard drives, and the protection of having a copy on object storage offsite with the ultimate data integrity.


