Whenever you want to send more than two or three files to someone, chances are you’ll zip the files to do so. The .zip file format, originally created by computer programmer Phil Katz in 1986, has become ubiquitous; indeed, the dictionary definition of the word zip includes this usage of zip as a verb.
If your web application allows end users to download files, it’s natural that you’d want to provide the ability to select multiple files and download them as a single .zip file. Aside from the fact that downloading a single file is straightforward and familiar, the files are compressed, saving download time and bandwidth.
There are a few ways you can provide this functionality in your application, and some are more efficient than others. Today, inspired by a question from a Backblaze customer, I’m talking through a web application I created that allows you to implement .zip downloads in your application with data stored in Backblaze B2 Cloud Storage.
If you’re ready to rock, jump straight to the docs. Otherwise, read on for more on how I got there.
First: Avoid this mistake
When writing a web application that stores files in a cloud object store such as Backblaze B2 Cloud Storage, a simple approach to implementing .zip downloads would be to:
- Download the selected files from cloud object storage to temporary local storage.
- Compress them into a .zip file.
- Delete the local source files.
- Upload the .zip file to cloud object storage.
- Delete the local .zip file.
- Supply the user with a link to download the .zip file.
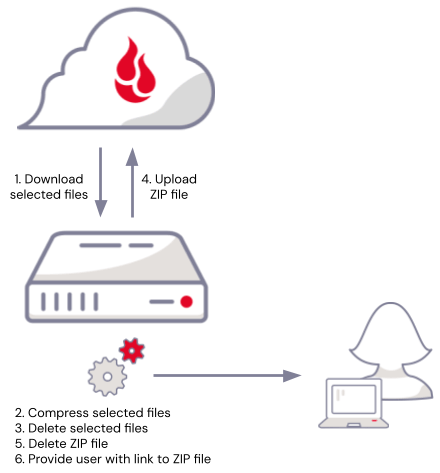
There’s a problem here, though—there has to be enough temporary local storage available to hold the selected files and the resulting .zip file. Not only that, but you have to account for the fact that multiple users may be downloading files concurrently. Finally, no matter how much local storage you provision, you also have to handle the possibility that a spike in usage might consume all the available local storage, at best making downloads temporarily unavailable, at worst destabilizing your whole web application.
Troubleshooting a better way
If you’re familiar with piping data through applications on the command line, the solution might already have occurred to you: Rather than downloading the selected files, compressing them, then uploading the .zip file, stream the selected files directly from the cloud object store, piping them through the compression algorithm, and stream the compressed data back to a new file in the cloud object store.
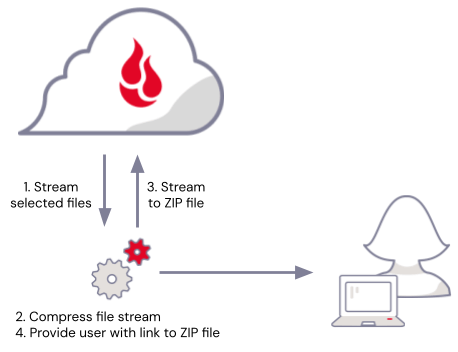
The web application I created allows you to do just that. I learned a lot in the process, and I was surprised by just how compact the solution was, just a couple dozen lines of code, once I’d picked the appropriate tools for the job.
I was familiar with Python’s zipfile module, so it was a logical place to start. The zipfile module provides tools for compressing and decompressing data, and follows the Python convention in working with file-like objects. A file-like object provides standard methods, such as read() and/or write(), even though it doesn’t necessarily represent an actual file stored on a local drive. Python’s file-like objects make it straightforward to assemble pipelines that read from a source, operate on the data, and write to a destination—exactly the problem at hand.
My next thought was to reach for the AWS SDK for Python, also known as Boto3. Here’s what I had in mind:
b2_client = boto3.client('s3')
# BytesIO is a binary stream using an in-memory bytes buffer
with BytesIO() as buffer:
# Open a ZipFile object for writing to the buffer
with ZipFile(buffer, 'w') as zipfile:
for filename in selected_filenames:
# ZipInfo represents a file within the ZIP
zipinfo = ZipInfo(filename)
# You need to set the compress_type on each ZipInfo
# object - it is not inherited from the ZipFile!
zipinfo.compress_type = ZIP_DEFLATED
# Open the ZipInfo object for output
with (zipfile.open(zipinfo, 'w') as dst):
# Get the selected file from B2
response = b2_client.get_object(
Bucket=input_bucket_name,
Key=filename,
)
# Copy the file data to the archive member
copyfileobj(response['Body'], dst, COPY_BUFFER_SIZE)
# Rewind to the start of the buffer
buffer.seek(0)
# Upload the buffer to B2
b2_client.put_object(
Body=buffer,
Bucket=output_bucket_name,
Key=zip_filename,
)
While the above code appears to work just fine, there are two issues. First, the maximum size of a file uploaded with a single put_object call is 5GB, and, second, the BytesIO object, buffer, holds the entire .zip file in memory. It may well be that your users will never select enough files to produce a .zip file greater than 5GB, but there is still a similar problem to the approach we started with: There needs to be enough memory available to hold all of the .zip files being concurrently created by users. We’re no further forward; in fact we’ve gone backwards–we traded a limited, but relatively cheap resource, disk space, for a more limited, more expensive resource: RAM!
It’s straightforward to upload files greater than 5GB using multipart uploads, splitting the file into multiple parts between 5MB and 5GB. I could rewrite my code to split the compressed data into chunks of 5MB, but that would add significant complexity to what seemed like it should be a simple task. I decided to try a different approach.
S3Fs is a “Pythonic” file interface to S3-compatible cloud object stores, such as Backblaze B2, that builds on Filesystem Spec (fsspec), a project to provide a unified Pythonic interface to all sorts of file systems, and aiobotocore, an asynchronous client for AWS. As well as handling details such as multipart uploads, allowing you to to write much more concise code, S3Fs allows you to write data to a file-like object, like this:
# S3FileSystem reads its configuration from the usual config files,
# environment variables. Alternatively, you can pass configuration
# to the constructor.
b2fs = S3FileSystem()
# Create and write to a file in cloud object storage exactly as you
# would a local file.
with b2fs.open(output_path, 'wb') as f:
for element in some_collection:
data = some_serialization_function(element)
f.write(data)
Using S3Fs, my solution for arbitrarily large .zip files was about the same number of lines of code as my previous attempt. In fact, I realized that the app should get each selected file’s last modified time to set the timestamps in the .zip file correctly, so this version actually does more:
zip_file_path = f'{output_bucket_name}/{zip_filename}'
# Open the ZIP file for output, open a ZipFile object
# for writing to the ZIP file
with b2fs.open(zip_file_path, 'wb') as f, ZipFile(f, 'w') as zipfile:
for filename in selected_filenames:
input_path = f'{input_bucket_name}/{filename}'
# Get file info, so we have a timestamp and
# file size for the ZIP entry
file_info = b2fs.info(input_path)
last_modified = file_info['LastModified']
date_time = (last_modified.year, last_modified.month, last_modified.day,
last_modified.hour, last_modified.minute, last_modified.second)
# ZipInfo represents a file within the ZIP
zipinfo = ZipInfo(filename=filename, date_time=date_time)
# You need to set the compress_type on each ZipInfo
# object - it is not inherited from the ZipFile!
zipinfo.compress_type = ZIP_DEFLATED
# Since we know the file size, set it in the ZipInfo
# object so that large files work correctly
zipinfo.file_size = input_file_info['size']
# Open the selected file for input,
# open the ZipInfo object for output
with (b2fs.open(input_path, 'rb') as src,
zipfile.open(zipinfo, 'w') as dst):
# Copy the data across
copyfileobj(src, dst, COPY_BUFFER_SIZE)
You might be wondering, how much memory does this actually use? The copyfileobj() call, right at the very end, reads data from the selected files and writes it to the .zip file. copyfileobj() takes an optional length argument that specifies the buffer size for the copy, so you can control the tradeoff between speed and memory use. I set the default in the b2-zip-files app to 1MiB.
This solves the problems we initially ran into, allowing you to offer .zip downloads without maxing out disk storage or RAM. Check out the docs to use this in your application.
My last piece of advice… Other than an easy .zip file downloader, I took one big lesson away from this experiment: Look beyond the AWS SDKs next time you write an application that accesses cloud object storage. You may just find that you can save yourself a lot of time!