If you read a blog article that starts with “In today’s fast-paced business landscape…” you can be 99% sure that content is AI generated. While large language models (LLMs) like ChatGPT, Gemini, and Claude may be the shiniest of AI applications from a consumer standpoint, they still have a ways to go from a creativity standpoint.
That said, there are exciting possibilities for artificial intelligence and machine learning (AI/ML) algorithms to improve and create products now and in the future, many of which focus on replicated operations, split second database predictions, natural language processing, threat analysis, and more. As you might imagine, deployment of those algorithms comes with its own set of complexities.
To solve for those complexities, specialized operations platforms have sprung up—specifically, AI/ML model serving platforms. Let’s talk about AI/ML model serving and how it fits into “today’s fast-paced business landscape.” (Don’t worry—we wrote that one.)
What Is AI/ML Model Serving?
AI/ML model serving refers to the process of deploying machine learning models into production environments where they can be used to make predictions or perform tasks based on real-time or batch input data.
Trained machine learning models are made accessible via APIs or other interfaces, allowing external applications or systems to send real-world data to the models for inference. The served models process the incoming data and return predictions, classifications, or other outputs based on the learned patterns encoded in the model parameters.
Practically, you can compare building an application that uses an AI/ML algorithm to a car engine. The whole application (the engine) is built to solve a problem; in this case “transport me faster than walking.” There are various subtasks to help you solve that problem well. Let’s take the exhaust system as an example. The exhaust fundamentally does the same thing from car to car—it moves hot air off the engine—but once you upgrade your exhaust system (i.e. add an AI algorithm to your application), you can tell how your engine works differently by comparing your car’s performance to a base-level model of the same one.
Now let’s plug in our “smart” element, and it’s more like your exhaust has the ability to see that your car has terrible fuel efficiency, identifies that it’s because you’re not removing hot air off the engine well enough, and re-route the pathway it’s using through your pipes, mufflers, and catalytic converters to improve itself. (Saving you money on gas—wins all around.)
Model serving, in this example, would be a shop that specializes in installing and maintaining exhausts. They’re experts at plugging in your new exhaust and having it work well with the rest of the engine even if it’s a newer type of tech (so, interoperability via API), and they have thought through and created frameworks for how to make sure the exhaust is functioning once you’re driving around (i.e. metrics). They’ve got a ton of ready-made parts and exhaust systems to recommend (that’s your model registry). When they install your new system in your engine, they might have some tweaks that work specifically in your system, too (versioning over time to serve your specific product).
Ok, back to the technical details. From an architecture standpoint, model serving also lets you separate your production model from the base AI/ML model in addition to creating an accessible endpoint (read: an API or HTTPS access point, etc.). This separation has benefits—making tracking model drift and versioning simpler, for instance.
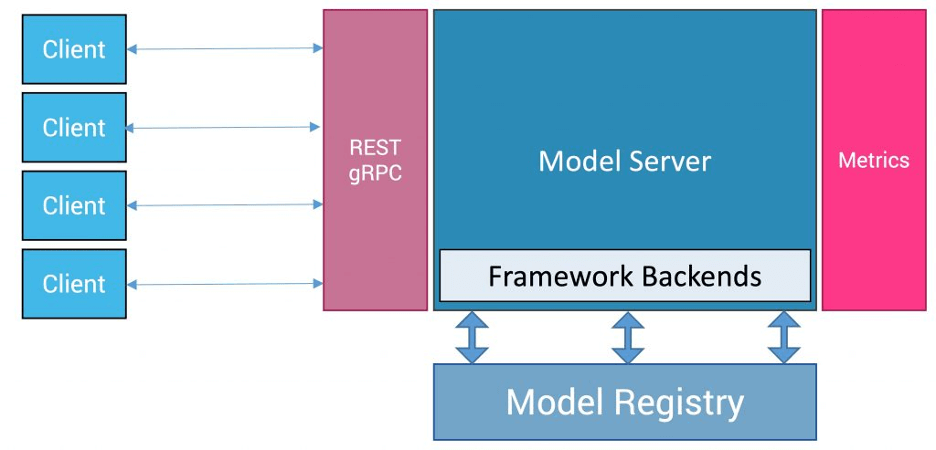
Like traditional software engineering, most AI/ML model serving platforms also have code libraries of fully or partially trained models—the model registry in the image above. For example, if you’re running a photo management application, you might grab an image recognition model and plug it into your larger application.
This is a tad more complex than other types of code deployment because you can’t really tell if an AI/ML model is functioning correctly until it’s working on real-world data. Certainly, that’s somewhat true of all code deployments—you always find more bugs when you’re live—but because AI/ML models are performing complex tasks like making predictions, natural language processing, etc., even a trained model has more room for “error” that becomes evident when it’s in a live environment. And, in many use cases—like fraud detection or network intrusion detection—models need to have very low latency to perform properly.
Because of that, deciding what kind of code deployment to use can have a high impact on your end users. For example, lots of experts recommend leveraging shadow deployment techniques, where your AI/ML model is ingesting live data, but running on a parallel environment invisible to end users, for phase one of your deployment.
Machine Learning Operations (MLOps) vs. AI/ML Model Serving
In reading about model serving, you’ll inevitably also come across folks talking about MLOps as well. (An Ops for every occasion, as they say. “They” being me.) You can think of MLOps as being responsible for the entire, end-to-end process, whereas AI/ML model serving focuses on one part of the process. Here’s a handy diagram that outlines the whole MLOps lifecycle:
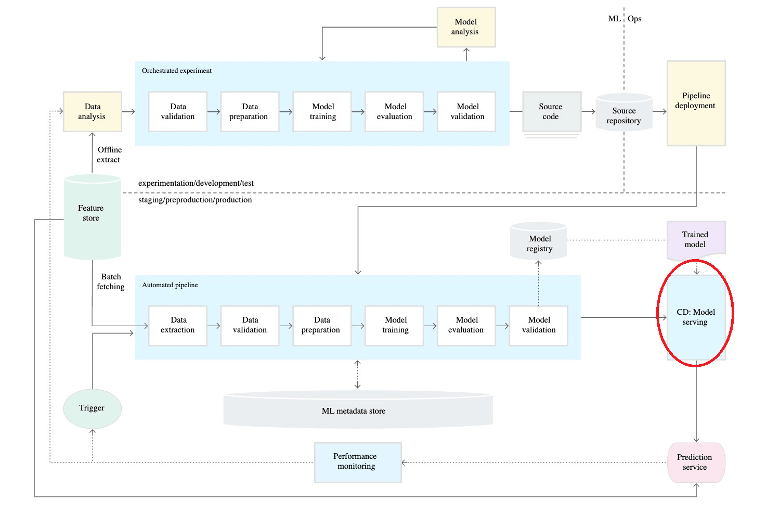
And, of course, you’ll see one box on there that’s called “model serving”.
How to Choose a Model Serving Platform
AI model serving platforms typically provide features such as scalability to handle varying workloads, low latency for real-time predictions, monitoring capabilities to track model performance and health, versioning to manage multiple model versions, and integration with other software systems or frameworks.
Choosing the right one is not a one-size-fits-all approach. Model serving platforms give you a whole host of benefits, operationally speaking—they deliver better performance, scale easily with your business, integrate well with other applications, and give you valuable monitoring tools from both a performance and security perspective. But, there are a ton of other factors that can come into play that aren’t immediately apparent, such as preferred code languages (Python is right up there), the processing/hardware platform you’re using, budget, what level of control and fine-tuning you want over APIs, how much management you want to do in-house vs. outsourcing, how much support/engagement there is in the developer community, and so on.
Popular Model Serving Platforms
Now that you know what model serving is, you might be wondering how you can use it yourself. We rounded up some of the more popular platforms so you can get a sense of the diversity in the marketplace:
- TensorFlow Serving: An open-source serving system for deploying machine learning models built with TensorFlow. It provides efficient and scalable serving of TensorFlow models for both online and batch predictions.
- Amazon SageMaker: A fully managed service provided by Amazon Web Services (AWS) for building, training, and deploying machine learning models at scale. SageMaker includes built-in model serving capabilities for deploying models to production.
- Google Cloud AI Platform: A suite of cloud-based machine learning services provided by Google Cloud Platform (GCP). It offers tools for training, evaluation, and deployment of machine learning models, including model serving features for deploying models in production environments.
- Microsoft Azure Machine Learning: A cloud-based service offered by Microsoft Azure for building, training, and deploying machine learning models. Azure Machine Learning includes features for deploying models as web services for real-time scoring and batch inferencing.
- Kubernetes (K8s): While not a model serving platform in itself, Kubernetes is a popular open-source container orchestration platform that is often used for deploying and managing machine learning models at scale. Several tools and frameworks, such as Kubeflow and KFServing, provide extensions for serving models on Kubernetes clusters.
- Hugging Face: Known for its open-source libraries for natural language processing (NLP), Hugging Face also provides a model serving platform for deploying and managing natural language processing models in production environments.
The Practical Approach
In short, AI/ML model serving platforms make ML algorithms much more manageable and accessible for all kinds of applications. Choosing the right one (as always) comes down to your particular use case—so, test thoroughly, and let us know what’s working for you in the comments.