
A simple question inspired this blog: At what size of RAID should you have a two-drive tolerance instead of one for your NAS device? The answer isn’t complex per se, but there were enough “if/thens” that we thought it warranted a bit more explanation.
So today, I’m explaining everything you need to know to choose the right RAID level for your needs, including their benefits, drawbacks, and different use cases.
Refresher: What’s NAS? What Is RAID?
NAS stands for network attached storage. It is an excellent solution for organizations and users that require shared access to large amounts of data. NAS provides cost-effective, centralized storage that can be accessed by multiple users, from different locations, simultaneously. However, as the amount of data stored on NAS devices grows, the risk of data loss also increases.
This is where RAID levels come into play. RAID stands for redundant array of independent disks (or “inexpensive disks” depending on who you ask), and it’s crucial for NAS users to understand the different RAID levels so they can effectively protect data while ensuring optimal performance of their NAS system.
Both NAS devices and RAID are disk arrays. That is, they are a set of several hard disk drives (HDDs) and/or solid state drives (SSDs) that store large amounts of data, orchestrating the drives to work as one unit. The biggest difference is that NAS is configured to work over your network. That means that it’s easy to configure your NAS device to support RAID levels—you’re combining the RAID’s data storage strategy and the NAS’s user-friendly network capabilities to get the best of both worlds.
What Is RAID Storage?
RAID was first introduced by researchers at the University of California, Berkeley in the late 1980s. The original paper, “A Case for Redundant Arrays of Inexpensive Disks (RAID)”, was authored by David Patterson, Garth A. Gibson, and Randy Katz, where they introduced the concept of combining multiple smaller disks into a single larger disk array for improved performance and data redundancy.
They also argued that the top-performing mainframe disk drives of the time could be beaten on performance by an array of the inexpensive drives. Since then, RAID has become a widely used data storage technology in the data storage industry, and many different levels of RAID levels evolved over time.
What Are the Different Types of RAID Storage Techniques?
Before we learn more about the different types of RAID levels, it’s important to understand the different types of RAID storage techniques so that you will have a better understanding of how RAID levels work. There are essentially three types of RAID storage techniques—striping, mirroring, and parity.
Striping
Striping distributes your data over multiple drives. If you use a NAS device, striping spreads the blocks that comprise your files across the available hard drives simultaneously. This allows you to create one large drive, giving you faster read and write access since data can be stored and retrieved concurrently from multiple disks. However, striping doesn’t provide any redundancy whatsoever. If a single drive fails in the storage array, all data on the device can be lost. Striping is usually used in combination with other techniques, as we’ll explore below.
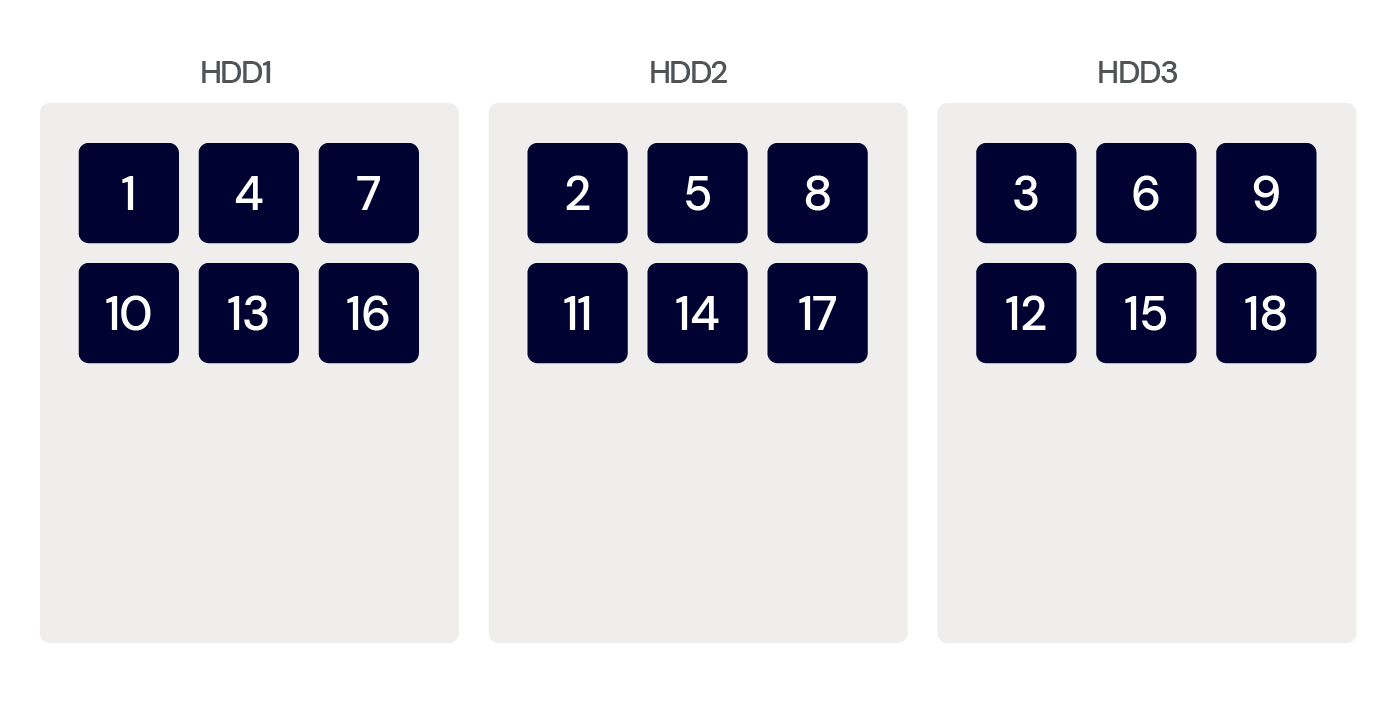
Mirroring
As the name suggests, mirroring makes a copy of your data. Data is written simultaneously to two disks, thereby providing redundancy by having two copies of the data. Even if one disk fails, your data can still be accessed from the other disk.
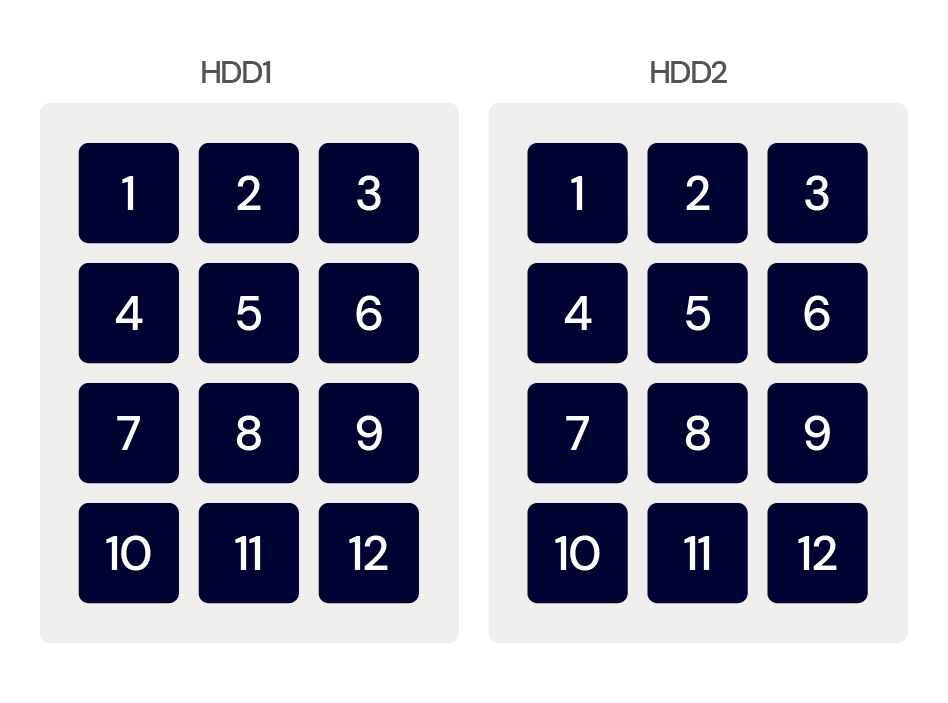
There’s also a performance benefit here for reading data—you can request blocks concurrently from the drives (e.g. you can request block 1 from HDD1 at the same time as block 2 from HDD2). The disadvantage is that mirroring requires twice as many disks for the same total storage capacity.
Parity
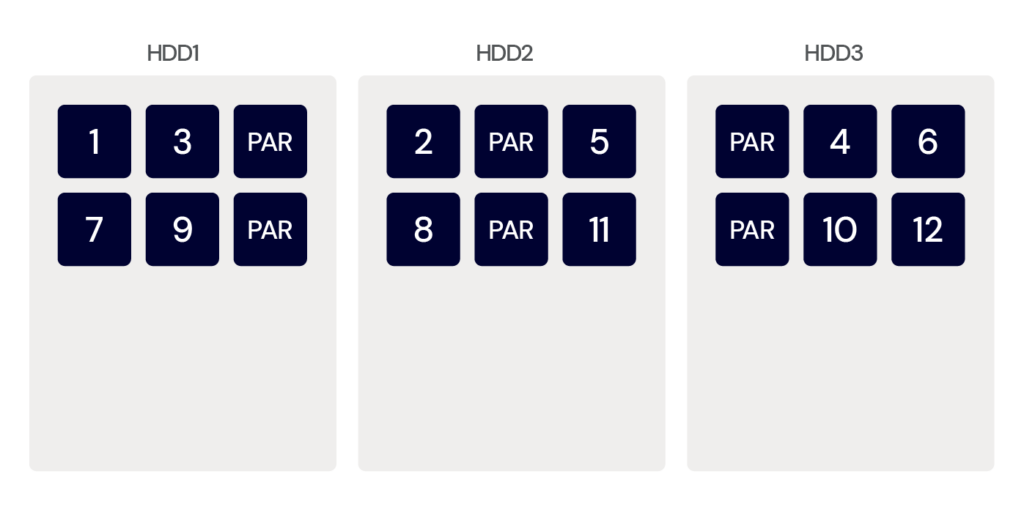
Parity is all about error detection and correction. The system creates an error correction code (ECC) and stores the code along with the data on the disk. This code allows the RAID controller to detect and correct errors that may occur during data transmission or storage, thereby reducing the risk of data corruption or data loss due to disk failure. If a drive fails, you can install a new drive and the NAS device will restore your files based on the previously created ECC.
What Is RAID Fault Tolerance?
In addition to the different RAID storage techniques mentioned above, the other essential factor to consider before choosing a RAID level is RAID fault tolerance.” RAID fault tolerance refers to the ability of a RAID configuration to continue functioning even in the event of a hard disk failure.
In other words, fault tolerance gives you an idea on how many drives you can afford to lose in a RAID level configuration, but still continue to access or re-create the data. Different RAID levels offer varying degrees of fault tolerance and redundancy, and it’s essential to understand the trade-offs in storage capacity, performance, and cost as we’ll cover next.
What Are the Different RAID Levels?
Now that you understand the basics of RAID storage, let’s take a look at the different RAID level configurations for NAS devices, including their benefits, use cases, and degree of fault tolerance.
RAID levels are standardized by the Storage Networking Industry Association (SNIA) and are assigned a number based on how they affect data storage and redundancy. While RAID levels evolved over time, the standard RAID levels available today are RAID 0, RAID 1, RAID 5, RAID 6, and RAID 10. In addition to RAID configurations, non-RAID drive architectures also exist like JBOD, which we’ll explain first.
JBOD: Simple Arrangement, Data Written Across All Drives
JBOD, also referred to as “Just a Bunch of Disks” or “Just a Bunch of Drives”, is a storage configuration where multiple drives are combined as one logical volume. In JBOD, data is written in a sequential way, across all drives without any RAID configuration. This approach allows for flexible and efficient storage utilization, but it does not provide any data redundancy or fault tolerance.
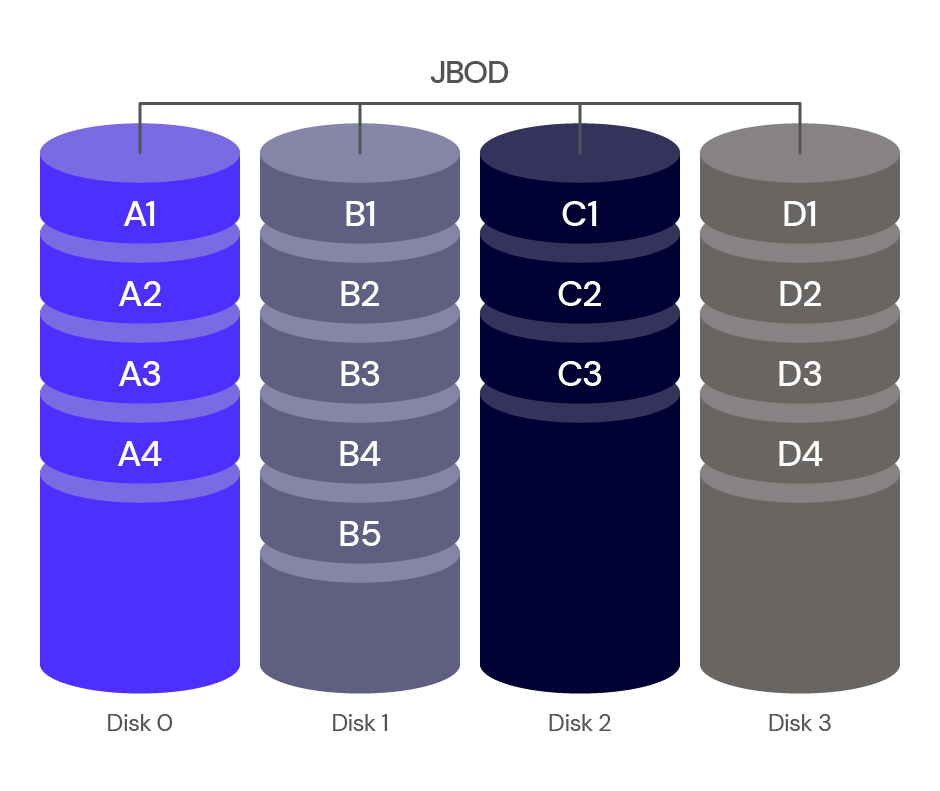
JBOD has no fault tolerance to speak of. On the plus side, it’s the simplest storage arrangement, and all disks are available for use. But, there’s no data redundancy and no performance improvements.
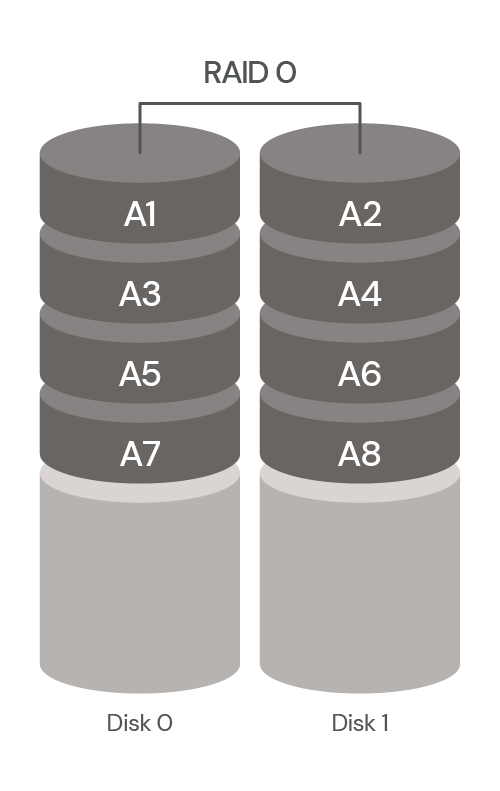
RAID 0: Striping, Data Evenly Distributed Over All Disks
RAID 0, also referred to as a “stripe set” or “striped volume”, stores the data evenly across all disks. Blocks of data are written to each disk in the array in turn, resulting in faster read and write speeds. However, RAID 0 doesn’t provide fault tolerance or redundancy. The failure of one drive can cause the entire storage array to fail, resulting in total loss of data.
RAID 0 also has no fault tolerance. There are some pros: it’s easy to implement, you get faster read/write speeds, and it’s cost effective. But there’s no data redundancy and an increased risk of data loss.
Raid 0: The Math
We can do a quick calculation to illustrate how RAID 0, in fact, increases the chance of losing data. To keep the math easy, we’ll assume an annual failure rate (AFR) of 1%. This means that, out of a sample of 100 drives, we’d expect one of them to fail in the next year; that is, the probability of a given drive failing in the next year is 0.01.
Now, the chance of the entire RAID array failing–its AFR–is the chance that any of the disks fail. The way to calculate this is to recognize that the probability of the array surviving the year is simply the product of the probability of each drive surviving the year. Note: we’ll be rounding all results in this article to two significant figures.
Multiply the possibility of one drive failing by the number of drives you have. In this example, there are two.
0.99 x 0.99 = 0.98
Subtract that result from one to calculate the percentage. So, the AFR is:
1 – 0.98 = 0.02, or 2%
So the two-drive RAID array is twice as likely to fail as a single disk.
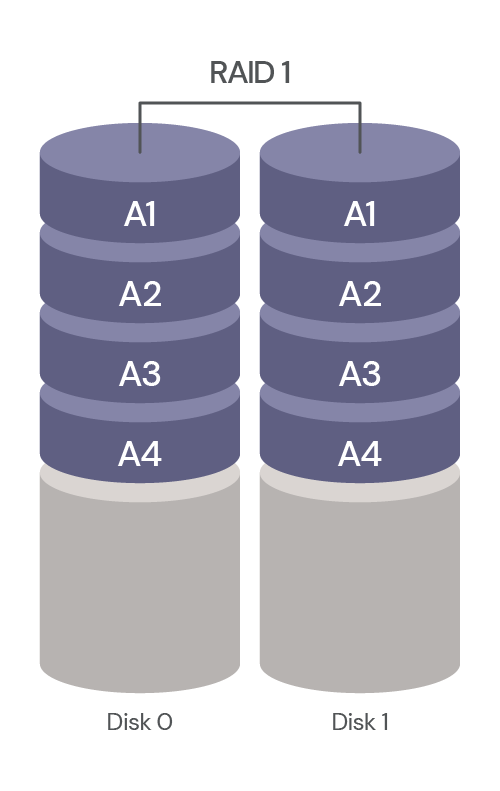
RAID 1: Mirroring, Exact Copy of Data on Two or More Disks
RAID 1 uses disk mirroring to create an exact copy of a set of data on two or more disks to protect data from disk failure. The data is written to two or more disks simultaneously, resulting in disks that are identical copies of each other. If one disk fails, the data is still available on the other disk(s). The array can be repaired by installing a replacement disk and copying all the data from the remaining drive to the replacement. However, there is still a small chance that the remaining disk will fail before the copy is complete.
RAID 1 has a fault tolerance of one drive. Advantages include data redundancy and improved read performance. Disadvantages include reduced storage capacity compared to disk potential. It also requires twice as many disks as RAID 0.
RAID 1: The Math
To calculate the AFR for a RAID 1 array, we need to take into account the time needed to repair the array—that is, to copy all of the data from the remaining good drive to the replacement. This can vary widely depending on the drive capacity, write speed, and whether the array is in use while it is being repaired.
For simplicity, let’s assume that it takes a day to repair the array, leaving you with a single drive. The chance that the remaining good drive will fail during that day is simply (1/365) x AFR:
(1/365) x 0.01 = 0.000027
Now, the probability that the entire array will fail is the probability that one drive will fail and also the remaining good drive fail during that one-day repair period:
0.01 x 0.000027 = 0.00000027
Since there are two drives, and so two possible ways for this to happen, we need to combine the probabilities as we did in the RAID 0 case:
1 – (1 – 0.00000027) x 2 = 0.00000055 = 0.000055%
That’s a tiny fraction of the AFR for a single disk—out of two million RAID arrays, we’d expect just one of them to fail over the course of a year, as opposed to 20,000 out of a population of two million single disks.
When AFRs are this small, we often flip the numbers around and talk about reliability in terms of “number of nines.” Reliability is the probability that a device will survive the year. Then, we just count the nines after the decimal point, disregarding the remaining figures. Our single drive has reliability of 0.99, or two nines, and the RAID 0 array has just a single nine with its reliability of 0.98.
The reliability of this two-drive RAID 1 array, given our assumption that it will take a day to repair the array, is:
1 – 0.00000055 = 0.99999945
Counting the nines, we’d also call this six nines.
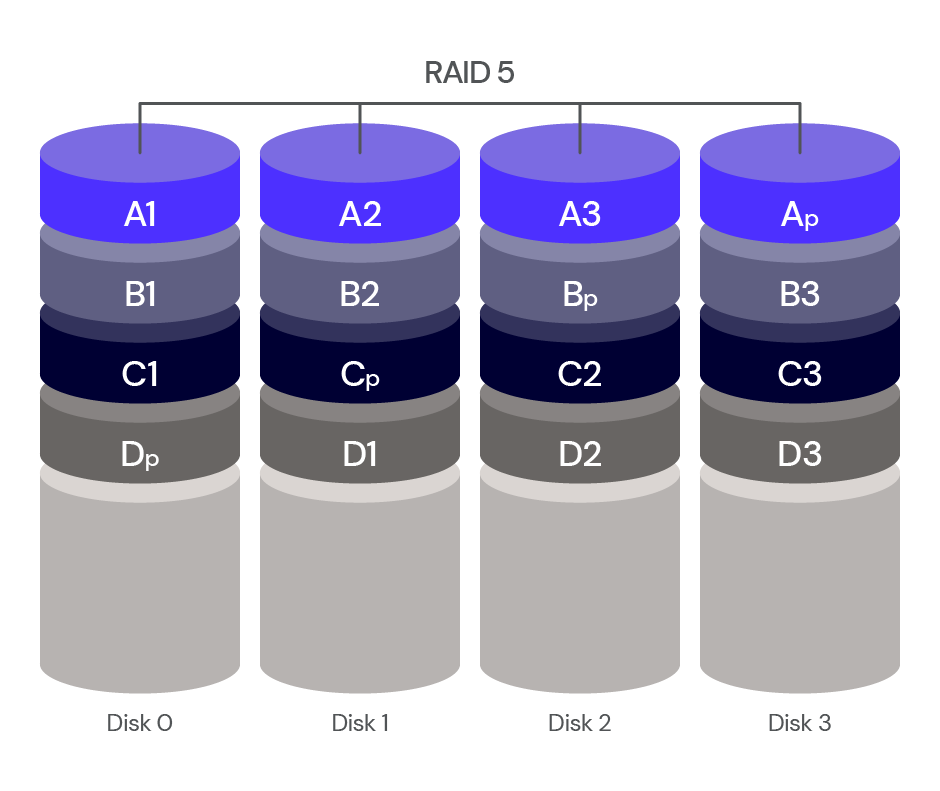
RAID 5: Striping and Parity With Error Correction
RAID 5 uses a combination of disk striping and parity to distribute data evenly across multiple disks, along with creating an error correction code. Parity, the error correction information, is calculated and stored in one block per stripe set. This way, even if there is a disk failure, the data can be reconstructed using error correction.
RAID 5 also has a fault tolerance of one drive. On the plus side, you get data redundancy and improved performance. It’s a cost-effective solution for those who need redundancy and performance. On the minus side, you only get limited fault tolerance: RAID 5 can only tolerate one disk failure. If two disks fail, data will be lost.
RAID 5: The Math
Let’s do the math. The array fails when one disk fails, and any of the remaining disks fail during the repair period. A RAID 5 array requires a minimum of three disks. We’ll use the same numbers for AFR and repair time as we did previously.
We’ve already calculated the probability that either disk fails during the repair time as 0.000027.
And, given that there are three ways that this can happen, the AFR for the three-drive RAID array is:
1 – (1 – 0.000027)3 = 0.000082 = 0.0082%
To calculate the durability, we’d perform the same operation as previous sections (1 – AFR), which gives us four nines. That’s much better durability than a single drive, but much worse than a two-drive RAID 1 array. We’d expect 164 of two million three-drive RAID 5 arrays to fail. The tradeoff is in cost-efficiency—67% of the three-drive RAID 5 array’s disk space is available for data, compared with just 50% of the RAID 1 array’s disk space.
Increasing the number of drives to four increases the available space to 75%, but, since the array is now vulnerable to any of the three remaining drives failing, it also increases the AFR, to 0.033%, or just one nine.
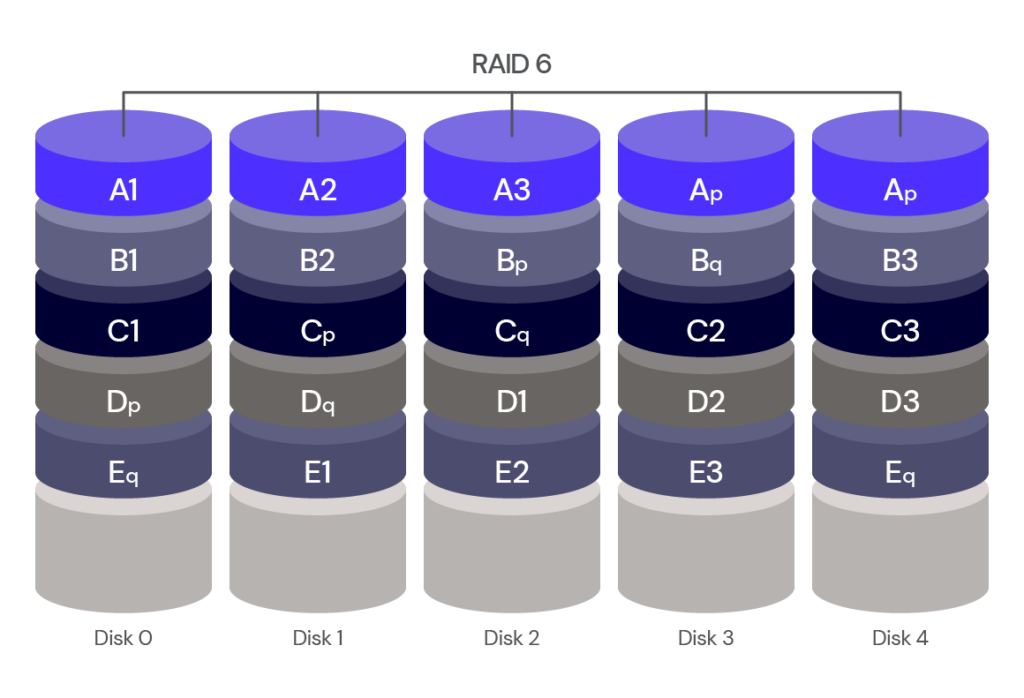
RAID 6: Striping and Dual Parity With Error Correction
RAID 6 uses disk striping with dual parity. As with RAID 5, blocks of data are written to each disk in turn, but RAID 6 includes two parity blocks in each stripe set. This provides additional data protection compared to RAID 5, and a RAID 6 array can withstand two drive failures and continue to function.
With RAID 6, you get a fault tolerance of two drives. Advantages include higher data protection and improved performance. Disadvantages include reduced write speed. Due to dual parity, write transactions are slow. It also takes longer to repair the array because of its complex structure.
RAID 6: The Math
The calculation for a four-drive RAID 6 array is similar to the four-drive RAID 5 case, but this time, we can calculate the probability that any two of the remaining three drives fail during the repair. First, the probability that a given pair of drives fail is:
(1/365) x (1/365) = 0.0000075
There are three ways this can happen, so the probability that any two drives fail is:
1 – (1 – 0.0000075)3 = 0.000022
So the probability of a particular drive failing, then a further two of the remaining three failing during the repair is:
0.01 * 0.000022 = 0.00000022
There are four ways that this can happen, so the AFR for a four-drive RAID array is therefore:
1 – (1 – 0.000000075)4 = 0.0000009, or 0.00009%
Subtracting our result from one, we calculate six nines of durability. We’d expect just two drives out of approximately two million to fail within a year. It’s not surprising that the AFR is similar to RAID 1, since, with a four-drive RAID 6 array, 50% of the storage is available for data.
As with RAID 5, we can increase the number of drives in the array, with a corresponding increase in the AFR. A five-drive RAID 6 array allows use of 60% of the storage, with an AFR of 0.00011%, or five nines; two of our approximately two million drives would fail.
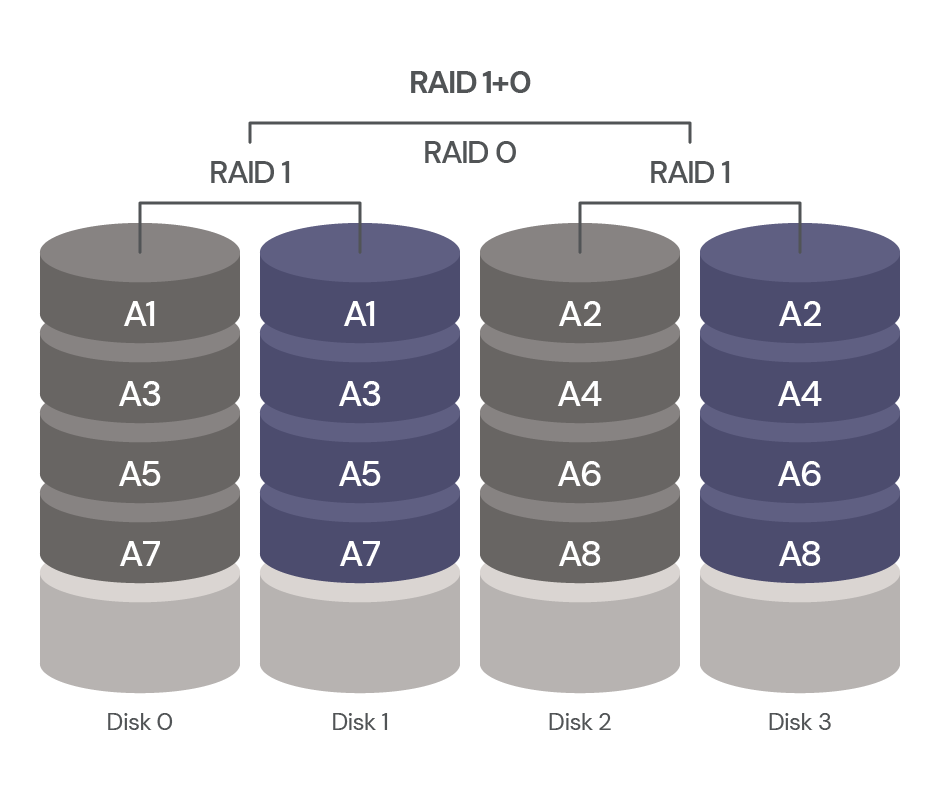
RAID 1+0: Striping and Mirroring for Protection and Performance
RAID 1+0, also known as RAID 10, is a combination of RAID 0 and RAID 1, in which it combines both striping and mirroring to provide enhanced data protection and improved performance. In RAID 1+0, data is striped across multiple mirrored pairs of disks. This means that if one disk fails, the other disk on the mirrored pair can still provide access to the data.
RAID 1+0 requires a minimum of four disks, of which two will be used for striping and two for mirroring, allowing you to combine the speed of RAID 0 with the dependable data protection of RAID 1. It can tolerate multiple disk failures as long as they are not in the same mirrored pair of disks.
With RAID 1+0, you get a fault tolerance of one drive per mirrored set. This gives you high data protection and improved performance over RAID 1 or RAID 5. However, it comes at a higher cost as it requires more disks for data redundancy. Your storage capacity is also reduced (only 50% of the total disk space is usable).
The below table shows a quick summary of the different RAID levels, their storage methods, and their fault tolerance levels.
| RAID Level | Storage Method | Fault Tolerance | Advantages | Disadvantages |
|---|---|---|---|---|
| JBOD | Just a bunch of disks | None |
|
|
| RAID 0 | Block-level striping | None |
|
|
| RAID 1 | Mirroring | One drive |
|
|
| RAID 5 | Block-level striping with distributed parity | One drive |
|
|
| RAID 6 | Block-level striping with dual distributed parity | Two drives |
|
|
| RAID 1+0 | Block-level striping with mirroring | One drive per mirrored set |
|
|
How Many Parity Disks Do I Need?
We’ve limited ourselves to the standard RAID levels in this article. It’s not uncommon for NAS vendors to offer proprietary RAID configurations offering features such as the ability to combine different sizes of disks into a single array, but the calculation usually comes down to fault tolerance, which is the same as the number of parity drives in the array.
The common case of a four-drive NAS device, assuming a per-drive AFR of 1% and a repair time of one day:
| RAID Level | Storage Method | Fault Tolerance Level | Notes |
|---|---|---|---|
| RAID 2 | Bit-level striping, variable number of dedicated parity disks | Variable | More complex than RAID 5 and 6 with negligible gains. |
| RAID 3 | Byte-level striping, dedicated parity drive | One drive | Again, more complex than RAID 5 and 6 with no real benefit. |
| RAID 4 | Block-level striping, dedicated parity drive | One drive | The dedicated parity drive is a bottleneck for writing data, and there is no benefit over RAID 5. |
RAID 5, dedicating a single disk to parity, is a good compromise between space efficiency and reliability. Its AFR of 0.033% equates to an approximately one in 3000 chance of failure per year. If you prefer longer odds, then you can move to mirroring or two parity drives, giving you odds of between one in one million and one in three million.
A note on our assumptions: In our calculations, we assume that it will take one day to repair the array in case of disk failure. So, as soon as the disk fails, the clock is ticking! If you have to go buy a disk, or wait for an online order to arrive, that repair time increases, with a corresponding increase in the chances of another disk failing during the repair. A common approach is to buy a NAS device that has space for a “hot spare”, so that the replacement drive is always ready for action. If the NAS device detects a drive failure, it can immediately bring the hot spare online and start the repair process, minimizing the chances of a second, catastrophic, failure.
Even the Highest RAID Level Still Leaves You Vulnerable
Like we said, answering the question “What RAID level do you need?” isn’t super complex, but there are a lot of if/thens. Now, you should have a good understanding of the different RAID levels, the fault tolerance they provide, and their pros and cons. But, even with the highest RAID level, your data could still be vulnerable.
While different RAID levels offer different levels of data redundancy, they are not enough to provide complete data protection for NAS devices. RAID provides protection against physical disk failures by storing multiple copies of NAS data on different disks to achieve fault tolerance objectives. However, it does not protect against the broader range of events that could result in data loss, including natural disasters, theft, or ransomware attacks. Neither does RAID protect against user error. If you inadvertently delete an important file from your NAS device, it’s gone from that array, no matter how parity disks you have.
Of course, that assumes you have no backup files. To ensure complete NAS data protection, it’s important to implement additional measures for a complete backup strategy, such as off-site cloud backup—not that we’re biased or anything. Cloud storage solutions are an effective tool to protect your NAS data with a secure, off-site cloud backup, ensuring your data is secured against various data loss threats or other events that could affect the physical location of the NAS.
At the end of the day, taking a multi-layered approach is the safest way to protect your data. RAID is an important component to achieve data redundancy, but additional measures should also be taken for increased cyber resilience.
We’d love to hear from you about any additional measures you’re taking to protect your NAS data besides RAID. Share your thoughts and experiences in the comments below.


